Asteroids are small, rocky bodies that orbit the sun and can be found throughout our solar system. They are of particular interest to scientists and space agencies because they can provide valuable resources and insights into the early history of the solar system.
One challenge in studying asteroids is detecting and tracking them. There are millions of asteroids in our solar system, and only a small fraction have been discovered and characterized. However, advances in technology and data analysis are making it possible to detect and track asteroids more effectively.
One approach that has gained popularity in recent years is using machine learning algorithms to detect and classify asteroids. Machine learning algorithms are computer programs that can learn from data and make predictions or decisions without being explicitly programmed.
For example, imagine that you have a dataset of asteroid observations, including their size, shape, and orbital characteristics. You could use a machine learning algorithm to classify asteroids into different categories, such as “potentially hazardous” or “resource-rich.” This could help astronomers and space agencies prioritize which asteroids to study or explore further.
In addition to detecting asteroids, machine learning can also be used to predict the resource potential of asteroids. For example, you could use a machine learning algorithm to predict the metal content of an asteroid based on its size, shape, and other characteristics. This could be valuable information for companies that are interested in asteroid mining.
To train a machine learning model for asteroid detection or resource prediction, you would need a large dataset of asteroid observations. This dataset could include information about the asteroids’ physical characteristics, such as their size, shape, and composition, as well as their orbital characteristics, such as their distance from the sun and their eccentricity.
Once you have collected and cleaned your data, you would need to choose a machine learning algorithm and train it on the data. There are many algorithms to choose from, including decision trees, random forests, and support vector machines (SVMs). Each algorithm has its own strengths and weaknesses, and the best choice for your problem will depend on the specific characteristics of your data.
After training the model, you can use it to make predictions or classifications on new data. For example, if you have trained a model to classify asteroids as “potentially hazardous” or “non-hazardous,” you can use it to classify a new asteroid that has just been discovered.
Overall, machine learning is a powerful tool for detecting and studying asteroids. It can help astronomers and space agencies identify and prioritize asteroids for further study, and it can also help companies interested in asteroid mining to predict the resource potential of different asteroids. As machine learning algorithms and datasets continue to improve, we can expect to see even more advances in asteroid detection and mining in the future.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import Pipeline
# Load the data
data = pd.read_csv('asteroid_data.csv')
# Impute missing values with the most common value
imputer = SimpleImputer(strategy='most_frequent')
data_imputed = imputer.fit_transform(data)
# Standardize the data
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data_imputed)
# The resulting data is now ready to be used to train a machine learning model
# Visualize the distribution of the data before preprocessing
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
data['density'].plot(kind='hist', title='Density (before preprocessing)')
# Visualize the distribution of the data after preprocessing
plt.subplot(1, 2, 2)
pd.DataFrame(data_scaled)[2].plot(kind='hist', title='Density (after preprocessing)')
plt.show()
# Assume that your data is in a Pandas DataFrame called "data"
# and that you want to predict the "label" column using the other columns
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(data_scaled, data["estimated resource value"], test_size=0.2, random_state=42)
# Create a training DataFrame
train_data = pd.concat([pd.DataFrame(X_train), y_train], axis=1)
# Create a pipeline with a SimpleImputer transformer
pipeline = Pipeline([
('imputer', SimpleImputer(strategy='mean')),
('model', LinearRegression())
])
# Train the model using the pipeline
pipeline.fit(X_train, y_train)
# Save the training data to a CSV file
np.savetxt("training_data.csv", X_train, delimiter=",")
np.savetxt("training_labels.csv", y_train, delimiter=",")
# Save the test data to a CSV file
np.savetxt("test_data.csv", X_test, delimiter=",")
np.savetxt("test_labels.csv", y_test, delimiter=",")
# Make predictions on the test data
predictions = pipeline.predict(X_test)
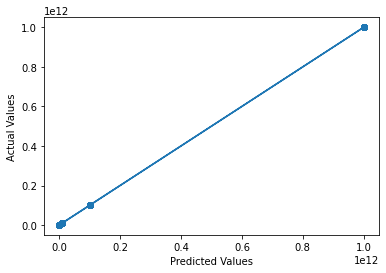
# Create a scatter plot of the predicted values versus the actual values
plt.scatter(predictions, y_test)
# Add a line of best fit
m, b = np.polyfit(predictions, y_test, 1)
plt.plot(predictions, m*predictions + b)
# Add axis labels
plt.xlabel("Predicted Values")
plt.ylabel("Actual Values")
# Show the plot
plt.show()
expo