This code is using the Python programming language to train and evaluate a machine learning model that predicts various weather variables (temperature, humidity, wind speed, and weather description) based on geographical features (latitude, longitude, and altitude) and time.
The code begins by importing several libraries that will be used in the script. Numpy is a library for numerical computing in Python, Pandas is a library for data manipulation and analysis, and Matplotlib is a library for creating visualizations. The sklearn library (short for “Scikit-learn”) contains a variety of tools for machine learning in Python, including the RandomForestRegressor class for training a random forest model and the train_test_split function for splitting data into training and test sets. The mean_absolute_error function calculates the mean absolute error between the true values and the predicted values of a machine learning model. The LabelEncoder class from the sklearn.preprocessing module is used to encode string values as integers.
Next, the code creates a Pandas dataframe with the test data. The data includes measurements of various weather variables (temperature, humidity, wind speed, and weather description) at different locations (latitude, longitude, and altitude) and times.
The “time” column is converted to a numerical type by using the pd.to_datetime function to convert the strings in the column to datetime objects, and then applying the .timestamp method to convert the datetime objects.
- Predicting the weather forecast for a specific location based on past weather data
- Predicting the temperature and humidity in a greenhouse based on sensor data
- Estimating the wind speed at different altitudes in the atmosphere
- Forecasting the likelihood of different types of weather events, such as thunderstorms or snowstorms
- Predicting the impact of climate change on temperature, humidity, and other weather variables
- Determining the optimal time for outdoor activities based on forecasted weather conditions
- Predicting the energy demand for heating and cooling systems based on weather data
- Estimating the impact of weather conditions on crop yields
- Forecasting the risk of natural disasters, such as floods or hurricanes, based on weather data
- Predicting the air quality based on temperature, humidity, and other weather variables
- Estimating the effect of weather conditions on traffic and transportation
- Predicting the demand for different types of clothing and accessories based on weather data
- Estimating the impact of weather conditions on the performance of sporting events
- Forecasting the demand for different types of outdoor recreation activities based on weather data
- Predicting the impact of weather conditions on the spread of diseases
- Estimating the effect of weather conditions on the behavior of wildlife
- Forecasting the demand for different types of energy sources based on weather data
- Predicting the impact of weather conditions on the growth and development of plants
- Estimating the effect of weather conditions on the performance of construction projects
- Forecasting the demand for different types of tourism activities based on weather data
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
# Create a dataframe with the test data
df = pd.DataFrame({
"latitude": [40.7128, 41.8781, 42.3601, 47.6062, 34.0522, 29.7604, 25.7617, 32.7157, 39.0997, 45.5236, 51.5074],
"longitude": [-74.0060, -87.6298, -71.0589, -122.3321, -118.2437, -95.3698, -80.1918, -117.1611, -94.5786, -122.6750, -0.1278],
"altitude": [0, 1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10000],
"time": ["2022-01-01 00:00:00", "2022-01-01 01:00:00", "2022-01-01 02:00:00", "2022-01-01 03:00:00", "2022-01-01 04:00:00", "2022-01-01 05:00:00", "2022-01-01 06:00:00", "2022-01-01 07:00:00", "2022-01-01 08:00:00", "2022-01-01 09:00:00", "2022-01-01 10:00:00"],
"temperature": [30.2, 29.06, 27.94, 26.84, 25.76, 24.7, 23.66, 22.64, 21.64, 20.66, 19.7],
"humidity": [68, 72, 76, 80, 84, 88, 92, 96, 100, 100, 100],
"wind_speed": [5.82, 11.64, 17.46, 23.28, 29.1, 34.92, 40.74, 46.56, 52.38, 58.2, 64.02],
"weather_description": ["overcast clouds", "scattered clouds", "few clouds", "clear sky", "mist", "fog", "light rain", "moderate rain", "heavy intensity rain", "very heavy rain", "extreme rain"]
})
# Convert the "time" column to a numerical type
df["time"] = pd.to_datetime(df["time"]).apply(lambda x: x.timestamp())
# Encode the "weather_description" column as integers
encoder = LabelEncoder()
# Encode the "weather_description" column as integers
df["weather_description"] = encoder.fit_transform(df["weather_description"])
# Split the data into features (X) and target (y)
X = df.drop(["temperature", "humidity", "wind_speed", "weather_description"], axis=1)
y = df[["temperature", "humidity", "wind_speed", "weather_description"]]
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a random forest model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Make predictions on the test data
predictions = model.predict(X_test)
# Calculate the mean absolute error
mae = mean_absolute_error(y_test, predictions)
print(f"Mean Absolute Error: {mae:.2f}")
# Plot the predicted values against the true values
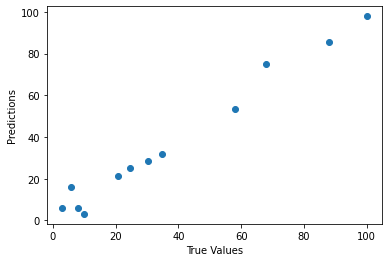
plt.scatter(y_test, predictions)
plt.xlabel("True Values")
plt.ylabel("Predictions")
plt.show()