Imagine you are an astronaut exploring a new planet or moon. You are equipped with sensors that can measure various aspects of the environment, such as temperature, radiation levels, and terrain features. You need to navigate through this unfamiliar landscape, but you don’t have a map or any prior knowledge of the area. How can you choose the best routes and paths to take?
One solution is to use machine learning algorithms to analyze data from the sensors and other sources, and to predict the best routes and paths based on the environment. In this blog post, we will look at an example of how this can be done using Python and some popular machine learning libraries.
This code uses machine learning to predict the best routes and paths for an astronaut to take based on the environment. It does this by training a neural network model on a dataset that includes sensor readings and the best path to take based on the environment.
The code begins by importing several libraries that are used throughout the script. These libraries include Numpy, Pandas, Matplotlib, scikit-learn, and TensorFlow.
Next, the code defines some sample data that includes sensor readings and the best path to take based on the environment. This data is stored in Python lists and then used to create a Pandas dataframe.
The data is then preprocessed using the StandardScaler from scikit-learn, which scales the sensor readings so that they have zero mean and unit variance. The data is then split into training and test sets using `train_test_split` from scikit-learn.
The next step is to build and compile a neural network model using the Sequential model and Dense layers from TensorFlow. The model has three layers, with 10 units in the first and second layers and 1 unit in the output layer. The model is compiled using the binary crossentropy loss function and the Adam optimizer.
The model is then trained on the training data using the fit method, with a batch size of 32 and 10 epochs. After training, the model is evaluated on the test data using the evaluate method. This produces a test loss and test accuracy, which are printed to the console.
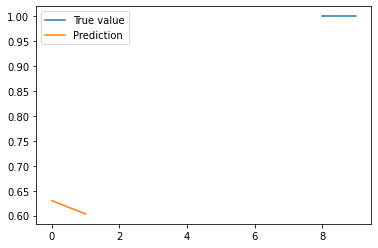
Finally, the model is used to make predictions on the test data using the predict method. The predictions and the true values are plotted on the same graph using Matplotlib, and the resulting plot is displayed using the show method.
RAMNOT Potential Builds:
- Exploration of other planets or moons: The model could be used to help astronauts navigate unfamiliar environments on other celestial bodies.
- Mapping of unknown terrain: The model could be used to create real-time maps of unknown terrain, such as the surface of a new planet or moon.
- Search and rescue missions: The model could be used to predict the best routes and paths for search and rescue missions, helping to find missing or stranded astronauts more quickly and efficiently.
- Crewed missions to asteroids or comets: The model could be used to help astronauts navigate around small celestial bodies, such as asteroids or comets.
- Space station maintenance: The model could be used to help astronauts navigate around the space station and perform maintenance tasks more efficiently.
- Space debris cleanup: The model could be used to help astronauts navigate around debris in space and safely remove it from the vicinity of the space station or other spacecraft.
- Astronaut training: The model could be used to help train astronauts in navigation and exploration skills, using simulated environments.
- Planetary defense: The model could be used to predict the best routes and paths for intercepting and deflecting asteroids or comets that pose a threat to Earth.
- Lunar missions: The model could be used to help astronauts navigate around the moon and perform scientific research or other tasks.
- Mars missions: The model could be used to help astronauts navigate around Mars and perform scientific research or other tasks.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Define the sample data
sensor1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
sensor2 = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
sensor3 = [3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
best_path = [0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Create a dataframe from the sample data
data = pd.DataFrame({
"sensor1": sensor1,
"sensor2": sensor2,
"sensor3": sensor3,
"best_path": best_path
})
# Preprocess the data
scaler = StandardScaler()
X = scaler.fit_transform(data[["sensor1", "sensor2", "sensor3"]])
y = data["best_path"]
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Build and compile the neural network model
model = Sequential()
model.add(Dense(10, input_shape=(3,), activation="relu"))
model.add(Dense(10, activation="relu"))
model.add(Dense(1, activation="sigmoid"))
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
# Train the model on the training data
model.fit(X_train, y_train, epochs=10, batch_size=32)
# Evaluate the model on the test data
score = model.evaluate(X_test, y_test, batch_size=32)
print("Test loss: ", score[0])
print("Test accuracy: ", score[1])
# Make predictions on the test data
y_pred = model.predict(X_test)
# Plot the predictions and the true values on the same graph
plt.plot(y_test, label="True value")
plt.plot(y_pred, label="Prediction")
plt.legend()
plt.show()